I recently hit a snag while developing a Jenkins pipeline at work. I was having difficulty preserving files across the entire pipeline run. In the end, my solution was to use the stash feature. However, I found little support for my specific type of issue online, so I figured I might as well write a short post about my experience.
Background
The pipeline runs an integration test suite I am working on. It contains mostly sequential stages, but there are a few that run in parallel. Specifically, there are provisioning and tear-down stages, one for each of the components we want to use during the testing.
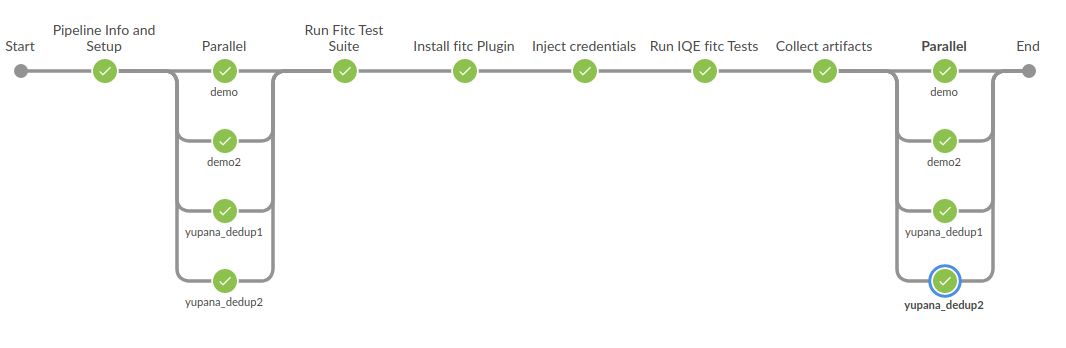
The Jenkins instance is hosted on Openshift, and uses containers for the job nodes. The pipeline uses several containers across the different stages, which means that the local filesystem does not persist throughout the entire pipeline. This was a problem, because we wanted to maintain metadata files from each of the provisioning stages, to use in dynamic tests, as well as during each tear down stage.
The issue is further complicated by the parallel provisioning stages. Each
provisioner runs in its own container, all at the same time. On top of that,
the number of provisioner/tear-down stages is dynamic. The pipeline might run
using data provisioners for components A, C, and D, in one run, and
A, B, C, G, and H for during next. It all depends on what
integration tests we want to perform. This meant that my solution also had to be dynamic and flexible.
My Plan
I looked briefly into changing the containers’ volume configuration, but my proof of concept pipeline hit a silent failure right away (the pipeline would endlessly hang, with no error). I decided to revisit that approach if my next plan (implementing stash and un-stash) didn’t work.
To simplify what to stash, and to have it work with the dynamically
changing parallel stages, I decided to try a single stash location. I made
a metadata directory that the stages could all write to, and stashed it. My
thought was that I could then un-stash it at the start of the first stage in
each subsequent node, and re-stash the contents at the end of a node.
sh "mkdir metadata"
sh "touch metadata/metadata_init" // Stash won't work with empty dirs
stash includes: 'metadata/', name: 'metadata', allowEmpty: true
unstash 'metadata'
I added the calls to my pipeline, having everything write to a
metadata stash. It was a good idea, but there was a problem…
My Problem
Because the stash is executed individually in parallel, only the files from the latest parallel stage were being saved and stored.
The Solution
As many issues in software, both the problem and the fix were rather simple. All I really did was change my stash call to used as documented. Still, I had trouble finding anything online talking about using stash the way I needed to, so I thought I’d share.
My solution was to continue to use the single directory method, but dynamically change the name of the stash during that initial parallel stage. It turns out, that the data was overwritten because each stash call had the same stash name, not because it was stashing the same directory.
I only need to parallel stash during the initial parallel stage, as the second one was at the end of the pipleline where the metadata would no longer be appended. So my plan was to dynamically stash each provisioner metadata, and then merge all the stashes into a single metadata stash to be used throughout the rest of the pipeline.
// Stash each builder's metadata if success
stash includes: 'metadata/', name: 'metadata-${testLabel}', allowEmpty: true
// Un-stash all successful builder metadata into single dir
for(label in testLabel) {
unstash "metadata-${label}"
}
Before making things complicated by unmerging to a different location from
where I wanted metadata to be, I first decided to see what happens if I
simply unstashed everything directly to the metadata dir. Luckily,
everything merged just fine with no overwrites. I even didn’t have to write
a merging function! Problem solved.
Conclusion
So that’s it. Often, the solution to a seemingly complicated problem is a simple one. This can be made more difficult if all of the online discussion seems tangential, but not exactly what you need. In those moments, it is probably best to pull aside a buddy to bounce ideas off of. Even if they don’t know how to immediately solve your problem, they can highlight problem areas that you might be able to find a solution in.
That is exactly how this solution surfaced. My friend Elyezer pointed out that the stashes were likely being over-written because they had the same stash name. Even though I knew that, having him re-emphasize it helped me zone in and work out the idea of dynamically making different stashes and merging them for the rest of the pipeline.
Teamwork. It makes a difference.
(P.S. Thanks Elyezer!)
Using Remote VSCode 2020 M1 Macbook Air Initial Thoughts